文本挖掘简介
时间:2016-10-13 作者:威尼斯569vip游戏 来源:本站原创
点击数:
l 文本挖掘的背景
A. 传统的自然语言理解是对文本进行较低层次的理解,主要进行基于词、语法和语义信息的分析,并通过词在句子中出现的次序发现有意义的信息
B. 文本高层次理解的对象可以是仅包含简单句子的单个文本,也可以是多个文本组成的文本集,但是现有的技术手段虽然基本上解决了单个句子的分析问题,但是还很难覆盖所有的语言现象,特别是对整个段落或篇章的理解还是无从下手。
C. 将数据挖掘的成果用于分析以自然语言描述的文本,这种方法被称为文本挖掘(Text Mining)或文本知识发现(Knowledge Discovery in Text)
l 文本挖掘与数据挖掘的区别
A. 文本挖掘:文档本身是半结构化的或非结构化的,无确定形式并且缺乏机器可理解的语义;
B. 数据挖掘:其对象以数据库中的结构化数据为主,并利用关系表等存储结构来发现知识
C. 因此,数据挖掘的技术不适用于文本挖掘,或至少需要预处理。
l 文本挖掘的过程
A. 特征抽取
u 定义:文本特征指的是关于文本的元数据
u 分类:
l 描述性特征:文本的名称、日期、大小、类型等。
l 语义性特征:文本的作者、标题、机构、内容等。
u 主要过程包括:
l 文本预处理:去掉html一些tag标记;禁用词去除、词根还原;分词、词性标注、短语识别等;词频统计;数据清洗。
l 文本表示:主要使用向量空间模型
l 降维技术:主要包括特征选择和特征重构
B. 特征选择:指从已有的M个特征(Feature)中选择N个特征使得系统的特定指标最优化,是从原始特征中选择出一些最有效特征以降低数据集维度的过程,是提高学习算法性能的一个重要手段,也是模式识别中关键的数据预处理步骤。
C. 文本分类:
u 定义:给定分类体系,将文本分到某个或者某几个类别中。
u 分类体系一般人工构造
n 政治、体育、军事
n 中美关系、恐怖事件
u 分类系统可以是层次结构,如yahoo!
u 分类模式
n 2类问题,属于或不属于(binary)类问题
n 多类问题,多个类别(multi-class),可拆分成2多类问题,多个类别(multi-class),可拆分成2类问题
u 一个文本可以属于多类(multi一个文本可以属于多类(multi-label)
u 文本分类过程如下图所示
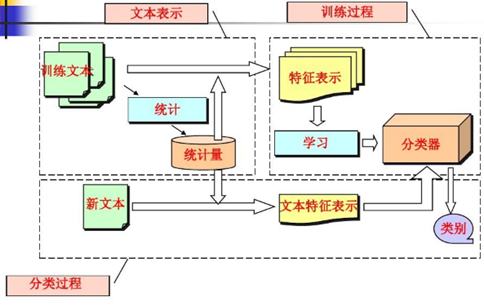
D. 文本聚类:
u 文档聚类主要是依据著名的聚类假设:同类的文档相似度较大,而不同类的文档相似度较小。作为一种无监督的机器学习方法,聚类由于不需要训练过程,以及不需要预先对文档手工标注类别,因此具有一定的灵活性和较高的自动化处理能力,已经成为对文本信息进行有效地组织、摘要和导航的重要手段,为越来越多的研究人员所关注。
E. 模型评价:指的是对我们所设计得到的模型的评价过程。主要从准确率、精度和查全率来判断模型的好坏。

